*** Please note that below document is based on the personal experience of using different HANA Information modeling constructs. The results of Performance tests depend upon the data volume and the Query filters. It is advisable to make the final judgement based on your own testing of such models.
Many of the reporting scenarios implement data comparison business case like “This Year to Last Year comparison” or similar. Such business requirement implementation in HANA can be done using the Calculation View model which is discussed in many of the presentations / training sessions. Something like shown below.






Many of the reporting scenarios implement data comparison business case like “This Year to Last Year comparison” or similar. Such business requirement implementation in HANA can be done using the Calculation View model which is discussed in many of the presentations / training sessions. Something like shown below.

Figure 1: Sample model with Projections for the Year on Year data comparison
The base model consists of creating projections over the Analytic view with the filter value for “This Year” Projection and “Last Year” Projection and a UNION node to combine the data for reporting.
Let's consider a sample data model based on Sales data. An Analytic view is created on the Sales base table and used in a Calculation view with Projections for This Year and Last Year data as shown in the sample model in Figure 1.

Figure 2: Sample data models based on Sales data for This Year and Last Year data comparison
In most of the cases, the general requirement is that, the user should provide "This Year" value (say Month and Year) and system should then return back data for the Month in This Year and for the Month in Last Year. Such data input can be captured and modeled in multiple ways.
This document outlines the impact on Performance of two such implementations of Filters in Projection. It explains the FILTER PUSH DOWN impact due to the different implementation options.
- Using Input Parameters for This Year Month and for Last Year Month
- Using Input Parameter for This Year Month and Calculated Column for Last Year Month
What is Filter Push Down:
When the data is queried on HANA Information models based on a subset defined by certain values, then the subset is defined using Filters. If the filters are implemented at the lowest level of dataset generation (Analytic search), then all the subsequent activities like aggregation happen on this reduced dataset. This provides high performance benefit.
If the filters are not implemented at the Analytic Search, then the entire data set is passed to the aggregation depending upon column joins and hence has negative impact on the performance.
To check if the filters are pushed down to the Analytic search, you need to find the “BWPopSearch” operation and check the details on the node in the visual plan. Please refer to the awesome blog by Lars Breddemann explaining the Visualize Plan tool.
Impact of using option 1: Using Input Parameters for This Year Month and for Last Year Month
In this implementation, two Input parameters are used
- For This Year Month - IP_TY_MONTH
- For Last Year Month - IP_LY_MONTH
The model can be created as shown below:

Figure 3: This Year and Last Year data comparison model using Input Parameters
The sample Sales data consists of few records for the Sales value in different months in different countries.
When such models are queried, then the Projection Filters are pushed down and the dataset exchanged between the OLAP engine and the Calc engine is quite less as the data is filtered in the OLAP engine and only the subset of the entire data required for the aggregation is passed to the Calc Engine. The execution plan for such query shows "Search" being performed as the first operation, reducing the dataset to be passed on for further processing.
Query:
SELECT "C_COUNTRY", "C_YEAR", "C_YEARMONTH", "ZPERIOD", sum("C_SALES") AS "C_SALES"
FROM "_SYS_BIC"."sample/ZGCV_SALES_TY_LY"
( 'PLACEHOLDER' = ('$$IP_LY_MONTH$$', '201201')
, 'PLACEHOLDER' = ('$$IP_TY_MONTH$$', '201301'))
WHERE "C_COUNTRY" = 'US'
GROUP BY "C_COUNTRY", "C_YEAR", "C_YEARMONTH", "ZPERIOD";
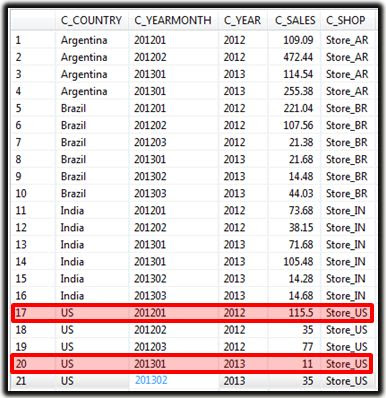
Sample data in the underlying Sales table:

Figure 4: Sales data in the underlying table
Output of the query:

Figure 5: Query output based on This Year month and Last Year month Input Parameters and Filter
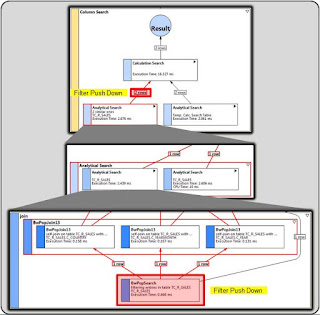
Execution Plan:

Figure 6: Execution plan for the Query with Projections based on Input Parameters
As seen in the Figure 6 above, the execution plan shows that the filters defined in the projection are pushed down to the OLAP engine resulting in a smaller data set which is passed to the Calc engine. This filter push down improves performance significantly in the Query execution. Hence to improve the performance, it is advisable to model the views so that the data is filtered much earlier.
Impact of using option 2: Using Input Parameters for This Year Month and Calculated Column for Last Year Month
This option provides the flexibility of the coding to derive the other filter values based on a given Input Parameter. It is quite natural to expect the users to provide value for ONLY ONE input parameter for a Projection filter and derive the other value based on the user provided value. Such coding can be achieved using Calculated columns.
*** Please note that currently the expression builder for Projection filter do not provide higher flexibility in data manipulation. Thus such manipulations need to be performed using Calculated Column. The expression builder for Calculated Column support wide variety of functions, enabling complex data manipulation.
In due course of time, I am very sure that the expression builder for Projection filter will support more functions.
The model for the Option 2 can be created as shown below:

Figure 7: This Year and Last Year data comparison model using Input Parameter and Calculated Column
When such models are queried, then the Projection Filter defined in the Calculated Column is NOT pushed down and the dataset exchanged between the OLAP engine and the Calc engine is quite large depending upon the column joins of the columns used in the Query. The entire data is passed to the Calc Engine where the subsequent filtering and aggregation happens. The execution plan for such query shows that NO Search operation happens in the OLAP engine. This has negative impact on the performance as large amount of data is exchanged between the engines and high memory and resources are required for the query execution.
Query:
SELECT "C_COUNTRY", "C_YEAR", "C_YEARMONTH", "ZPERIOD", sum("C_SALES") AS "C_SALES"
FROM "_SYS_BIC"."sample/ZGCV_SALES_TY_LY"
( 'PLACEHOLDER' = ('$$IP_LY_MONTH$$', '201201'))
WHERE "C_COUNTRY" = 'US'
GROUP BY "C_COUNTRY", "C_YEAR", "C_YEARMONTH", "ZPERIOD";
Sample data in the underlying Sales table and the output of the query remains same as for Option 1.
Execution Plan:

Figure 8: Execution plan for the Query with Projections based on Calculated Column and Input Parameter
As seen in the Figure 8 above, the execution plan shows that the filter defined in the projection using the Calculated Column is NOT pushed down to the OLAP engine resulting in large data set passed to the Calc engine. It is strongly recommended to look into the Query execution plan for the Information models and check the impact of such modeling constructs. It is advisable to ensure that the filters can be pushed down to the OLAP engine to improve the performance of the query. If possible, you may opt to change the existing model with Calculated Column to Input Parameters and have the data manipulation done for the values to be passed to the Input Parameters in the Front end reporting tool rather than in HANA. The User input Prompts in the front end reporting tool can be defined to capture one value and other value to be passed to the second Input Parameter can be derived from the first prompt value.
As mentioned at the start of this document, I would request fellow HANA practitioners to try and test their models and validate the performance impact of the queries.
Also as mentioned above, I am very positive that the filter expression for Projection will provide large set of data manipulation functions in future, which will enable writing better Filter conditions and will eliminate the need to define the Calculated Columns for filtering in the Information model completely.
Source: scn.sap.com
No comments:
Post a Comment